I recently had some extra free time for an exploratory project in Natural Language Processing. Due to my experience with audio engineering and interest in synthesizers, I chose to do my project on evaluating the MBROLA speech synthesizer alongside with the Festival text-to-speech synthesizer.
While both of these synths are diphone based, MBROLA pre-processes diphones which have constant pitch or harmonic phase, which gives it an ample boost in efficiency during the synthesis step.
I wanted to build a speech synthesizer which was:
-
Light on CPU resource usage,
-
Modular enough to accommodate post-processing
-
Able to perform real-time synthesis.
Based on these requirements, it seemed that MBROLA may provide a decent solution.
In order to meet my requirements, I decided to use the MBROLA synthesizer as an external node inside of a MAX/MSP visual programming environment, allowing for real-time communication between different nodes which could be set up to handle post-processing. I decided to record 3 distinct phrases using my voice and then feed the same 3 phrases through both of the synthesizers, both of which shared a common phoneme database (MBROLA voices).
After capturing both of the synthesizer’s outputs, I examined the spectral output in Praat Toolkit and compared the synthesized speech to the human generated recordings. I set Festival as my lower bound with my upper bound being the Human generated speech. I wanted to see how closely I could match the spectral output of MBROLA to the human generated wave forms as well as differentiate it’s output from the traditional diphone synthesis of Festival.
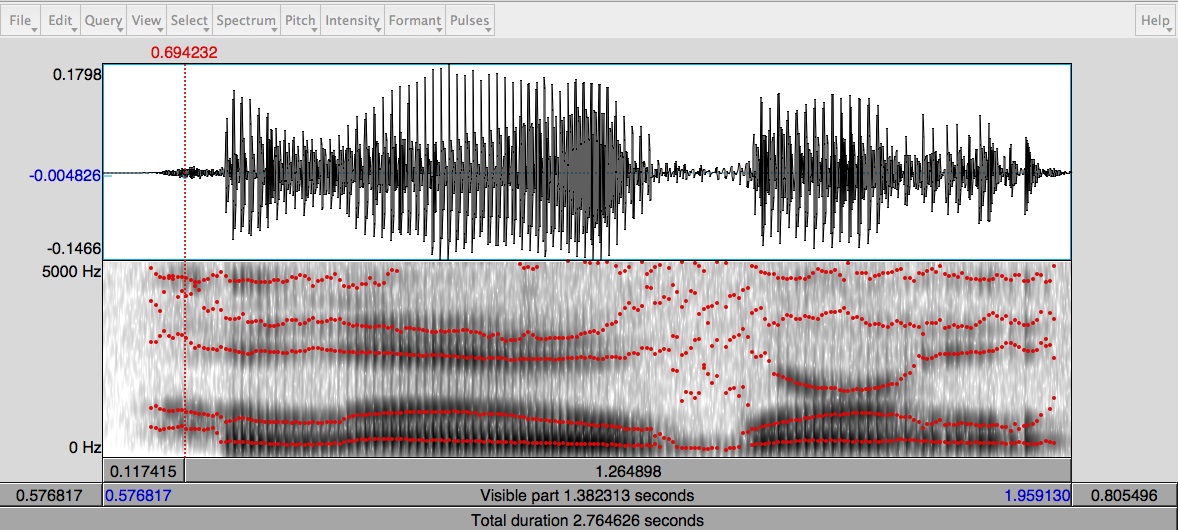
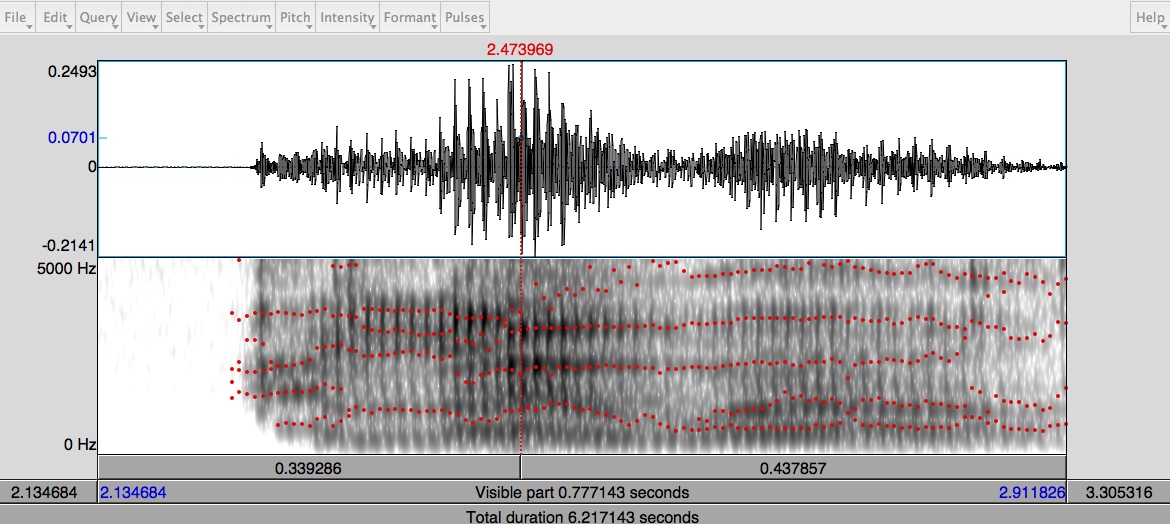
I was able to easily match the harmonic pitch of my voice, however, difficulty was encountered when trying to mimic the specific prosody and phrasing. After applying slight post-processing, mainly compression and EQ, I was able to generate a sound wave which matched my voice’s sound wave structure. However, try as I might, I could not erase some of the traces of computerized speech. In comparison to Festival, some phonemes sounded worse on MBROLA even after post-processing. These next two screens contain the human and MBROLA generated sound files of the phrase ‘Hello World’.
Human Generated Speech of phrase ‘Hello World’
MBROLA Generated Speech of phrase ‘Hello World’ (after post-processing).
Over all this was an enjoyable project and a welcomed return back into the world of audio. While the MBROLA synth didn’t really turn out the way I wanted it…. I still enjoyed evaluating the tool and setting up the MBROLA for Max external object in MAX/MSP.